
I Ditched Vector Embeddings for RAG. Here’s What Happened.
Like most developers who’ve touched AI tooling in the last two years, my first instinct for building a document search system was the standard playbook: chunk the text, embed it with an LLM, shove it into a vector database, and query by cosine similarity. It works. It’s well-documented. Everyone does it.
But I kept asking myself a nagging question: do I actually need a vector database for this?
What started as a weekend experiment turned into a production-ready app, a new architectural pattern I now reach for by default, and a genuine shift in how I think about RAG. Here’s what I built, what surprised me, and when I’d (and wouldn’t) use this approach again.
The Experiment: What Is “Vectorless RAG”?
Traditional RAG looks like this:
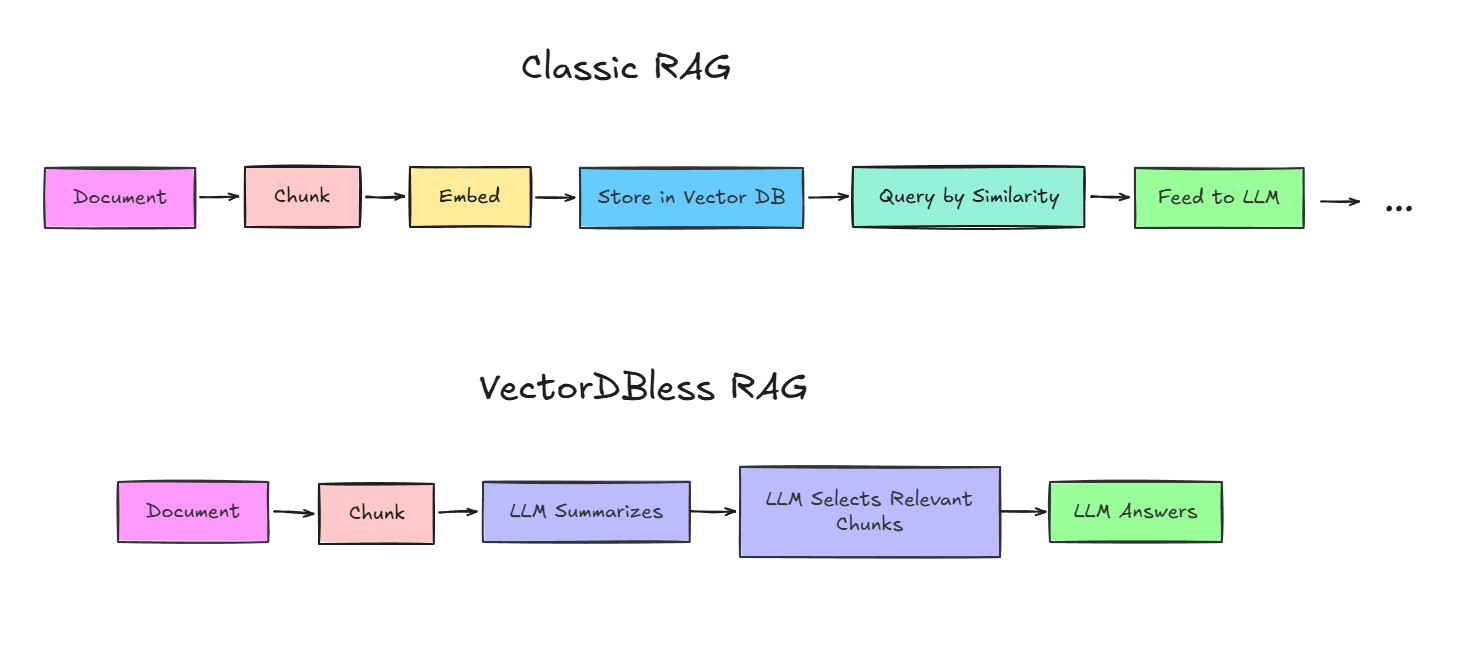
Instead of embedding text and hoping cosine similarity finds the right chunks, the LLM reads short summaries of every chunk and makes an informed decision about what’s actually relevant to the user’s question.
No vector database. No embedding model. No infrastructure beyond a single serverless function.
I built this on Cloudflare Workers with React Router 7 and TypeScript. The app lets you upload PDFs, ask natural language questions, and get structured answers back — all running at the edge. I’m covering the API costs so anyone can try it live and see the difference for themselves.
TL;DR
Vectorless RAG uses LLM-generated summaries instead of vector embeddings for retrieval. It’s cheaper, simpler, and more accurate for structured documents — but doesn’t scale to millions of files. Perfect for 1-50 document analysis where answer quality matters.
The Retrieval Technique, Explained Simply
The trick is in how retrieval works. Here’s the high-level flow:
-
Indexing — When you upload a document, it’s split into ~2,500-character chunks. For each chunk, a lightweight LLM call generates a 1–2 sentence summary. These summaries are stored in-memory alongside the full chunk text.
-
Querying — When you ask a question, the system sends all chunk summaries to the LLM in a single prompt and asks: “Which of these summaries contain information relevant to this question? Return the indices.”
-
Extraction — The full text of the selected chunks is retrieved. A second LLM call extracts structured data — deadlines, amounts, eligibility criteria, whatever the document type demands.
-
Answer — A cheap, fast model synthesizes a readable paragraph response from the extracted data.
The key insight: LLMs are excellent at relevance judgment when given the right context. A vector embedding can’t understand the difference between “What changed in the local business tax calculation?” and “What is the local business tax rate?” — but an LLM reading “Section 4.2: Updated local business tax base calculation rules” can, instantly.
Vectorless vs. VectorDB: The Real Numbers
I ran this side-by-side with a traditional vector RAG setup and tracked the differences. Here’s what I found:
| Metric | Vector RAG (OpenAI + Pinecone) | Vectorless RAG |
|---|---|---|
| Monthly cost | $50–100+ | Pennies (single Worker) |
| Infrastructure | Vector DB + embedding service + app server | Single serverless function |
| Setup complexity | 3–4 services to configure and maintain | 1 service |
| Inference time | Fast retrieval, but embedding pipeline adds latency | One LLM call per query |
| Answer quality | Good for keyword-heavy queries | Excellent for nuanced, semantic questions |
| Cold starts | None (persistent DB) | Minimal (edge function) |
Where Vectorless Wins
-
Cost. You’re not paying for embeddings, you’re not paying for a vector database, and you’re not paying for a separate app server. The entire system runs on a single Cloudflare Worker with a free-tier KV namespace for rate limiting.
-
Simplicity. There’s no schema to manage, no index to rebuild, no embedding model to swap out when a better one ships. The “index” is just an array of summaries in memory.
-
Contextual accuracy. For structured documents — legal texts, regulations, grant applications, official gazettes — the LLM’s ability to reason about summaries outperforms cosine similarity on nuanced questions. Vector search finds similar words. LLM retrieval finds relevant meaning.
Where VectorDB Still Wins
-
Scale. If you’re searching across millions of documents, sending thousands of summaries to an LLM per query is impractical. Vector search scales horizontally. Vectorless RAG doesn’t.
-
Speed. Embedding + similarity search is measured in milliseconds. LLM-based retrieval adds a model call. For real-time search across large corpora, vectors are still king.
-
Persistence. Vector databases persist. In-memory sessions reset on cold starts. If you need persistent document libraries across sessions, you’ll need to add KV or D1 storage.
Rule of thumb: Use Vectorless RAG for 1–50 documents per session where answer quality matters more than raw speed. Use VectorDB for large-scale, high-throughput search where milliseconds count.
Who This Is Actually For
I built this because I saw a real gap. Lawyers, tax advisors, grant consultants — people who work with dense, structured documents every day — don’t need a vector database. They need to upload a 200-page grant application or a Magyar Közlöny issue and ask: “What’s the deadline? Who’s eligible? What changed from the previous version?”
That’s what this does. And it does it for a fraction of what a traditional RAG stack costs.
For Developers
The full source code is available on Gumroad. It’s a complete, production-ready Cloudflare Workers project with React Router 7, TypeScript end-to-end, and a clean architecture you can fork and adapt. If you’ve been wanting to build a document analysis tool but didn’t want to manage a vector DB, this is your starting point.
For Legal & Tax Professionals
If you work with regulations, contracts, tax publications, or official gazettes — this is being built for you. The Pro version (currently in closed beta) adds persistent document libraries, multi-document search, exportable summaries, and dedicated support. Sign up for early access and you’ll get a permanent 50% discount at launch. Check.
For Enterprises
There’s a separate enterprise option on Gumroad for teams that need custom deployment, SLA guarantees, and dedicated infrastructure. If you’re evaluating this for your organization, reach out and we’ll talk through your requirements. Gumroad.
The Stack: React Router 7 and Full-Stack TypeScript
This project was also my first real dive into React Router 7, and I’ll be honest — it surprised me.
I went in expecting a routing library. What I got was a full-stack framework with built-in data loading, server-side actions, streaming responses, and end-to-end TypeScript type safety. The loader/action pattern eliminated the need for a separate API layer. Server-Sent Events for streaming query results were trivial to implement. The type system caught mismatches between my route handlers and UI components before they ever hit the browser.
For a solo developer shipping a production app, the developer experience was genuinely excellent. Less glue code, fewer moving parts, and a build pipeline that just worked. I’ll write a deeper post about the RR7 architecture soon — this one’s already long enough.
What I’d Do Differently
No experiment is perfect. If I rebuilt this today:
-
Persistent sessions. In-memory sessions are fine for a live demo, but production needs KV or D1-backed storage so documents survive cold starts.
-
System prompt separation. Right now, all LLM calls use
role: "user"only. Introducing a properrole: "system"layer would harden the app against prompt injection from uploaded documents. -
Batch summarization. Currently, each chunk gets its own LLM call during indexing. Batching chunks into a single prompt would cut indexing time and cost significantly.
The Takeaway
Vector embeddings aren’t going anywhere. They’re the right tool for large-scale search, and the ecosystem around them is mature and battle-tested.
But for the kind of document analysis most developers and professionals actually need — uploading a handful of PDFs and asking smart questions about them — the vector pipeline is overkill. It adds cost, complexity, and infrastructure without necessarily improving answer quality.
Sometimes the simplest architecture is the one that skips the database entirely and just asks the LLM to do what it’s already good at: read, reason, and respond.
Try It Out
- Try it live — no sign-up, no API key, just upload a PDF and ask a question.
- Get the source code — complete project on Gumroad, ready to deploy.
- Join the early access list — for legal and tax professionals who want the Pro version.
Questions to think about
- Would Vectorless RAG work for your use case?
- What’s the document scale you’re working with?
- Are you more cost-sensitive or performance-sensitive?